Possiamo scrivere la regola di apprendimento del perceptrone in
maniera più compatta, sempre assumendo
:
(12)
In questo modo non abbiamo bisogno di verificare che
. Abbiamo inserito il fattore
che controlla quanto la modifica influisce sul cambiamento di
. In particolare, il teorema di convergenza continua a
valere.
Fino a questo momento abbiamo avuto a che fare con il tempo
"discretizzato", vedremo ora brevemente come si può affrontare
l'apprendimento del perceptrone in termini di tempo continuo;
pertanto giungeremo ad una equazione differenziale che viene
considerata più conveniente del processo iterativo sopra
descritto, in riferimento al processo di apprendimento.
Misuriamo ora il tempo con l'unità , quindi:
Dopo un piccolo numero
, di iterazioni, il
vettore sarà cambiato solo di poco,
Per gli stadi intermedi possiamo quindi scrivere:
Dove è il vettore input al passo . Sommiamo i due
termini per :
da cui:
Facendo il limite per
e
otteniamo:
(13)
dove:
probabilità che il vettore venga estratto durante il
processo di apprendimento.
Anche per questa descrizione del processo di apprendimento vale
il teorema di convergenza che ora non dimostriamo:
Teorema: Se il compito è linearmente separabile,
allora l'equazione (13) converge ad un
punto fisso tale che
.
Next:Bibliography Up:L'apprendimento Previous:Il Perceptrone
Michele Cerulli
2000-10-29
![\begin{displaymath}
\sum^{n-1}_{l=0}J(t+l\epsilon+\epsilon)-\sum^{n-1}_{l=0}J(t...
...1}_{l=0}x_{l}[M(x_{l})-\theta(J(t)\cdot
x_{l}+o(n\epsilon))]
\end{displaymath}](img320.png)
![\begin{displaymath}
\frac{J(t+n\epsilon)-J(t)}{n\epsilon}=\frac{1}{n}
\sum^{n-1}_{l=0}x_{l}[M(x_{l})-\theta(J(t)\cdot
x_{l}+o(n\epsilon))]
\end{displaymath}](img321.png)
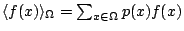
probabilità che il vettore
venga estratto durante il processo di apprendimento.
![\begin{displaymath}
\frac{d}{dt}J(t)=\langle x[M(x_{l}-\theta(J(t)\cdot
x)]\rangle_{\Omega}
\end{displaymath}](img324.png)