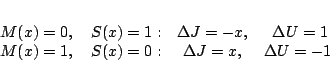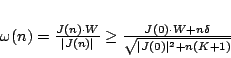modifica parametri:: ritorna al passo 1
: modifica i parametri e torna al passo 1
Lo scopo ultimo è quello di ottenere un neurone che riesca ad eseguire perfettamente l'operazione![$J\quad\rightarrow\quad J+\Delta J[J,U;x,M(x)]$](img260.png)
![$U\quad\rightarrow\quad U+\Delta U[J,U;x,M(x)]$](img261.png)
Iniziamo semplificando le equazioni introducendo la costante, ed identificando
per cui possiamo scrivere:
Learning rule:
Il nuovo insiemeora consiste di tutti i vettori del tipo
con
nell'insieme originale.