| << | >> | Indice |
|---|
Quando si realizzano pagine web conviene stare molto attenti ai nomi che si usano ed alle strutture delle directory, in quanto questi risultano fondamentali nel gioco dei link che sono individuati dal tag <a>. I link sono un elemento fondamentale delle pagine web, e sono la ragione per cui questi tipi di documenti vengono chiamati ipertesti. Un link non è altro che un'area del documento (che sia testo o immagine non importa), tale che, cliccandoci, vi porta ad un'altro documento (o attiva qualche programma), in sostanza essi sono i collegamenti tra i documenti, e costituiscono il principale mezzo, a disposizione dell'utente, per poter navigare in rete (non amo questa espressione, ma purtroppo ormai è universalmente accettato).Di conseguenza bisogna stare attenti a come definiamo questi link, in quanto ci possono essere delle situazioni in cui possiamo ottenere risultati inaspettati. Consideriamo il seguente esempio:
EsempioIo in questo momento sto lavorando sulla macchina sophie.dm.unipi.it, e voglio fare un link all'indice di questo seminario, allora ho, pe rlo meno, le tre seguenti possibilità:
Se clicchiamo sul primo link, questo sara accessibile solo ed esclusivamente se ci troviamo fisicamente a lavorare sulla macchine sophie.dm.unipi.it, o equivalentemente se il browser che stiamo usando è stato lanciato da una shell (magari in remoto) di sophie.dm.unipi.it. Il codice con cui è stato scritto il primo link è il seguente:
<li><a href="file:/home/www-studenti/cerulli/seminario/index.html"> Link assoluto rispetto alla macchina dove mi trovo </a></li>
Se clicchiamo tale link da una qualsiasi altra macchina, allora il browser cercherà il file "/home/www-studenti/cerulli/seminario/index.html" sulla macchina su cui stiamo lavorando, quindi quasi sicuramente non troverà niente ed otterremo una risposta, da parte del browser, del tipo "impossibile trovare la directory o il file specificato".
Proviamo a cliccare sul secondo link, questa volta non sarà il browser a risponderci, ma il server delle pagine web degli studenti a cui richiediamo la pagina specifica. Se questo documento si trova ancora su tale server allora ci verrà mostrato l'indice che cerchiamo, altrimenti ci verrà mostrata la una pagina web con il seguente messaggio:
Not Found
The requested URL /~cerulli/seminario/ci.html was not found on this server.
In questo caso la richiesta di documento era stata inoltrata, tramite l'attributo href direttamente al server httpd, il quale ha cercato il documento all'interno del proprio archivio; il link in questione è stato prodotto con il seguente codice:
<li><a href="http://www-studenti/~cerulli/seminario/index.html">
Link assoluto rispetto all'indirizzo web, ovvero URL assoluto
</a></li>
L'attributo href si definisce indicando il tipo di collegamento (ftp, http, file, etc.) e il luogo in cui andare a cercare il documento; nel caso di riferimenti dati in maniera assoluta rispetto agli indirizzi web, l'attributo href appare proprio come l'indirizzo web, URL, che un qualsiasi visitatore deve indicare al proprio browser per visitare il documento in questione.
Consideriamo infine il terzo link di quelli presentati. In questo caso, posso stare certo (modulo tragiche smentite) che qualsiasi utente riuscirà, tramite questo link, a raggiungere l'indice di qeusto seminario. In questo caso l'indirizzo è stato dato relativamente alla posizione del documento corrente nell'archivio del server che lo ospita; il codice usato è il seguente:
<li><a href="index.html">
Link relativo alla directory che contiene il file
</a></li>
In questo caso il demone httpd cerca il documento index.html nella directory dove si trova il documento corrente, ovvero consigli.htm. Se avessi voluto un docoumento nella directory superiore avrei dovuto definire href="../nomedelfile.html", mentre per un documento contenuto in una directory figlia di quella ospitante il corrente, avrei dovuto definire href="nomedirectoryfiglia/nomedelfile.html".
In Sostanza, il metodo ottimale di definire i link è quello relativo poichè ci garantisce che anche se spostiamo le pagine in blocco da una macchina all'altra, i link incrociati tra i vari documenti funzioneranno sempre. Questo può essere ad esempio il caso di quando lavoriamo sul nostro computer di casa e poi installiamo le pagine prodotte su un'altro computer.
I link definiti come URL assoluti (secondo ink dell'esempio) invece possono essere rognosi quando si cambia server, o quando, all'interno della stessa macchina, si spostano in blocco delle directory, ma esclusi questi casi sono piuttosto affidabili nel senso che, se ben definiti, sono accessibili da qualsiasi utente, proprio come nel caso dei link relativi.
Il peggior metodo, e decisamente sconsigliabile, è quello assoluto rispetto alla macchina, ovvero il primo esempio, in questo caso gli utenti esterni non saranno mai in grado di accedere al documento indicato dal link .... ovviamente ci possono essere dei casi in cui vogliamo che accada proprio questo!
Per concludere osserviamo che spesso, spostando dei files da una macchina all'altra, può capitare che i nomi dei files, se contengono caratteri speciali, possono alterarsi.Questo capita sicuramente se lavoriamo su qualche Windows ed il nome del file contiene degli spazi, se spostiamo il file su una macchina Linux gli spazi creeranno dei problemi; vice versa, se su linux chiamiamo un file con un nome molto lungo, quando lo trasportiamo in DOS questo verà tagliato (lo stesso accade passando da Windows a DOS). Le conseguenza di queste anomalie può essere che spostando le pagine web da un sistema operativo all'altro i link non funzionano più poichè sono cambiati i nomi dei files. Inoltre, spesso possono alterarsi anche alcuni caratteri contenuti nei files stessi.
Considerando quanto finora detto:
è buona regola organizzare razionalmente le directory contenenti le pagine web;
conviene stare attenti ai nomi che si usano per chiamare file, directory;
infine quando possibile utilizzate links relativi.
Gli editori in generale possono classificarsi in due grandi famiglie, quelli WYSIWYG, e quelli normali. In questo paragrafo daremo delle indicazioni molto generali sulla prima di queste due classi, ed analizzeremo alcune potenzialità di Emacs che appartiene invece alla classe di qeulli normali (non so se esiste un nome ufficiale per indicare questo tipo di editori).
Editori di tipo WYSIWYG: pro e contro
WYSIWYG sta per What You See Is What You Get, ovvero "qeullo che vedi è quello che otterrai", in altre parole questi editori sono quelli che permettono di lavorare direttamente sulla pagina bella e formattata, ovvero vedendo il suo aspetto finale in tempo reale, e permettono di agire direttamente sull'aspetto del documento, non sul codice con cui è codificato. Nel nostro caso un editore WYSIWYG può permetterci di dimenticarci dell'esistenza dell'HTML e di agire direttamente sulla pagina così come appare. Editori di questo tipo possono essere: Word, StarWriter, Composer, Word Perfect, e chi più ne ha più ne metta. Alcuni di questi, come Composer, sono nati per realizzare documenti HTML, altri, come ad esempio Word, sono nati per realizzare testi formattati in generale, ma permettono anche di realizzare pagine web. In generale è lecito aspettarsi che un editore fatto a posta per le pagine web produca un migliore html, ma non ci farei troppo affidamento.
I pro: i lati positivi nell'utilizzare questi editori risiedono essenzialmente nel fatto che non, con essi, è necessario conoscere, o imparare, l'HTML per realizzare pagine web, in quanto teoricamente permettono di creare pagine senza occuparsi minimamente del codice che ci sta sotto. Inoltre possono essere molto comodi se andiamo di fretta e non sappiamo bene come realizzare certe cose utilizzando l'HTML.
I contro: il fatto di non lavorare sulla sorgente HTML ci toglie il controllo di ciò che effettivamente accade, ovvero noi sappiamo come la pagine ci appare, ma non sappiamo assolutamente che tipo di codice HTML ci sta sotto; ovviamente su nosta richiesta anche gli editori WYSIWYG ci permettono di vedere la sorgente e di agire su di essa, se provate a farlo è che troverete molti "pasticci". Questi editori in genere sono abbastanza stupidi e solitamente non si preoccupano minimamente di ottimizzare il codice, tanto meno si occupano di tutte le questioni legate alla fruibilità delle pagine di cui abbiamo parlato nel precedente caiptolo. Vediamo alcune questioni specifiche:
Queste disattenzioni degli editori possono produrre:
Vi mostriamo ora un esempio del codice prodotto da un editore, confrontandolo con la versione da me ripulita a mano:
Vediamo ora il codice che sta dietro alle due pagine:
Non credo che ci sia bisogno di commentare la differenza tra i due files, osserviamo solo che il primo (nettamente più brutale ed obsoleto) occupa 23279 bites della memoria del computer, mentre quello ripulito occupa 3350 bites, ovvero approssimativamente 23K contro 3K, quindi, in questo caso, c'è un rapporto di circa 1/7; di conseguenza può capitare che magari realizziamo un documento che pootenzialmente occuperebbe 1 mega (facciamo un esempio sostanzioso), ma che "Microsoft FrontPage 3.0" fa diventare 7 mega .... e un utente qualsiasi non sarebbe affatto felice di scricare 7 mega!
Nel caso dell'esempio che vi ho mostrato, font e colori sono leggermente diversi per scelta estetica, ma se provate a cambiare le opzioni dei font del vostro browser scoprirete che magicamente vedrete le due tabelle rappresentate con i nuovi font che impostate: la sostanza è di nuovo che ammattire con i font è un lavoro totalmente inutile! Lo stesso può valere anche per i colori del testo, che possono essere cambiati dal browser dell'utente.
In conclusione, gli editori di tipo WYSIWYG possono essere molto comodi in quanto possono far risparmiare tempo, soprattutto se non si è esperti di HTML, e non necessitano che si conosca il linguaggio in question; d'altro canto vanno usati con cautela in quanto possono produrre un sacco di cose strane. Il mio consiglio è quello di utilizzarli quando si va di furia, oppure quando non sapete come ottenere un certo effetto, e poi magari andate un po' a ripulire il file a mano. Personalmente non uso praticamente mai editori di questo tipo, ma preferisco srivere direttamente in HTML in modo da tenere sotto controllo il codice prodotto.
Editori normali: Emacs
Per "editore normale" intendo un editore di testo semplice che, nel caso specifico dell'HTML, richiede di scrivere direttamente utilizzando il codice in questione. Editori di questo tipo sono generalmente utilizzati per scrivere in LaTex, o per scrivere programmi usando un qualsiasi linguaggio di programmazione. L'editore normale decisamente più popolare qui al Dipartimento di Matematica di Pisa è Emacs. Per chi lo conosce un po', questo editore ha una potenza mostruosa, è un fac-totum utile per un sacco di cose. In particolare ci interessa la modalitè html che generalmente si innesca automaticamente quando iniziamo ad editare un file .html, altrimenti si può innescare con "ESC x" e quindi digitando "html-mode". Chiaramente di Emacs esistono varie versioni, in particolare io mi riferirò ad Xemacs, che presenta un'interfaccia un pochino più carina, ma in sostanza quello che dirò vale anche per Emacs normale.
Supponiamo di voler produrre un file .html con XEmacs, possiamo lanciare da consolle (oppure Ctrl-x-f se il programma è già aperto) il comando "xemacs nuovo.html", il programma si aprirà e ci chiederà di inserire un titolo per il documento, ad esempio il titolo potrebbe essere "Nuovo"; una volta inserito, Xemacs produce lo scheletro del documento, di cui mostriamo uno screen-shot:
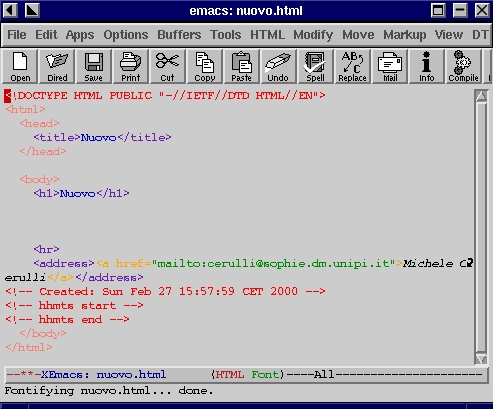
A questo punto possiamo iniziare a lavorare sul file; le cose di base veramente interessanti di questo ambiente di lavoro sono a mio avviso:
La cosa a mio avviso interessante è che Emacs può essere molto utile anche per imparare l'HTML grazie al fatto che ti suggerisce quali tag inserire nei vari punti, e che segnala se ci sono degli attributi mancanti. Insomma dal punto di vista dell'assistenza all'utente non ha niente da invidiare agli editori WYSIWYG, solo che permette di tenere sempre sotto controllo il codice e non prende iniziative dissennate! L'unica pecca di questo programma è appunto che quello che si guadagna in controllo del codice lo si perde nel fatto che non si vede direttamente la pagina così come appare agli occhi di un utente; ma si può facilmente sopperire a questa mancanza lavorando tenendo contemporaneamente emacs ed un browser, in modo da visualizzare sia il codice che i suoi effetti (ricaricando spesso la pagina).
Emacs è generalmente presente in ogni distribuzione di Linux, ed è gratis. Esiste una versione di Emacs anche per Windows, esiste almeno un altro programma ad esso equivalente che si chiama JED (gratis); potete trovare i due software nei seguenti siti:
| << | >> | Indice |
|---|